

「GEOをやりましょう」という話が増えてきました。マーケティング担当者だけでなく、ブランドオーナーや経営者からも同じ言葉を聞くようになっています。
ただ、正直に言うと、GEOとは何を最適化しているのか、正確に説明できる人はまだ少ない。「AIに引用されるようにコンテンツを整える」というのは正しい。でもその前に、AIがどういう仕組みでコンテンツを参照しているのかを理解しないと、施策が的外れになります。「Braveに登録しよう」「llms.txtを入れよう」。どちらも間違いではないのですが、なぜそれをするのかが分からないまま動くのはリスクです。
ブランドオーナーの方へ、先にひとつ。GEOは「新しい施策」ではありません。土台はSEOです。これまでコツコツ積み上げてきたSEOの資産が、AI時代の可視性にそのままつながっています。新しいものを追いかける前に、その話を先にしておきたい。
この記事では、AIがコンテンツを参照するプロセスを3つの層に分けて整理します。SEO担当者にとっては施策を評価するための地図として、ブランドオーナーにとっては投資の優先順位を判断するための視点として、使ってください。
AIはどうやってコンテンツを「知っている」のか
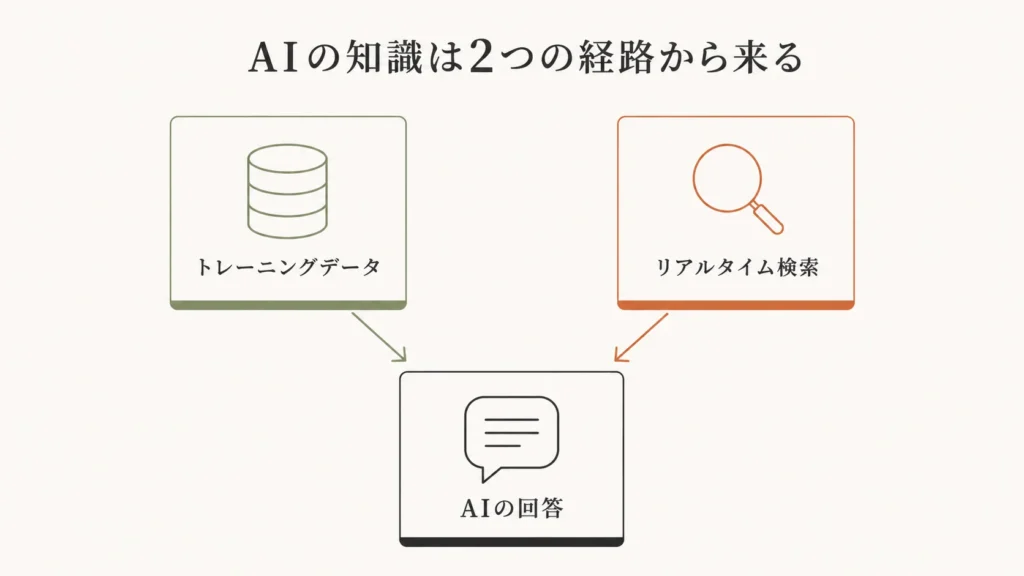
AIチャットボットがあなたの質問に答えるとき、その知識は2つの経路から来ています。
ひとつは、モデルが公開される前の学習(トレーニング)で焼き付いた知識。もうひとつは、質問が来たときにリアルタイムで検索して取ってくる情報。この2つは、まったく別のシステムです。
「AIに覚えさせる」「AIに学習させる」という言葉が広まったせいで、この2つが混同されています。GEOを正しく考えるには、まずここを切り分けることが先です。
AIの回答に自分のコンテンツが引用・参照される確率を高めるための最適化。ただしAIがコンテンツを参照するプロセスは一段階ではなく、3つの層に分かれている。どの層に何が起きているかを理解しないまま施策を打っても、空振りになる。
第1層:トレーニングデータ(モデルに焼き付いた知識)
AIモデルは公開される前に、膨大なウェブデータを使って学習しています。その中心になるのがCommon Crawl。2008年から運営している非営利団体が提供する公開ウェブアーカイブで、GPT-3ではトレーニングデータ全体のトークンの80%以上がここから取られていました。
Common Crawlはリアルタイムではなく、定期的なスナップショット形式でデータを収集・公開しています。これがカットオフ(知識の締め切り日)が構造的に存在する理由です。カットオフ以降の情報は、この層には存在しません。
自分のサイトがトレーニングデータに含まれているかどうかを確認する方法はありません。GPT-4のトレーニングコストは1億ドルを超えているとSam Altmanが発言しているように、モデルのトレーニングは数ヶ月〜数年単位の大規模プロセスです。個人や企業が後から「学習させる」ことは、仕組み上できません。
この層は、現実的に最適化できる層ではありません。
コンテンツを公開しても、それが現在稼働中のモデルの学習データに追加されるわけではない。トレーニングは大規模なプロセスであり、その対象データを外部からコントロールする手段は現時点で存在しない。
第2層:リアルタイム検索(クエリ時に起きること)
リアルタイム検索が発動するとき、AIは単純に「検索して表示する」わけではありません。AI検索システムの研究によれば、すべてのAI検索は共通の5段階パイプラインで動いています。
| ステージ | 名称 | 何が起きるか |
|---|---|---|
| 1 | 質問の理解 | クエリを解釈し、エンティティを特定。検索を発動するかどうかもここで判断される |
| 2 | クエリのファンアウト | 1つの質問を複数の内部サブクエリに展開。ニッチなコンテンツが広いクエリに引っかかる理由はここにある |
| 3 | 取得(Retrieval) | サブクエリを検索インデックスに問い合わせ、候補ページを取得。どのインデックスを使うかはAIによって異なる |
| 4 | 再ランキング(Re-ranking) | 取得した候補を、引用に適しているかという観点で再評価。ここで検索順位と引用が切り離される |
| 5 | 生成(Generation) | 上位の候補からAIが回答を生成し、引用を付ける |
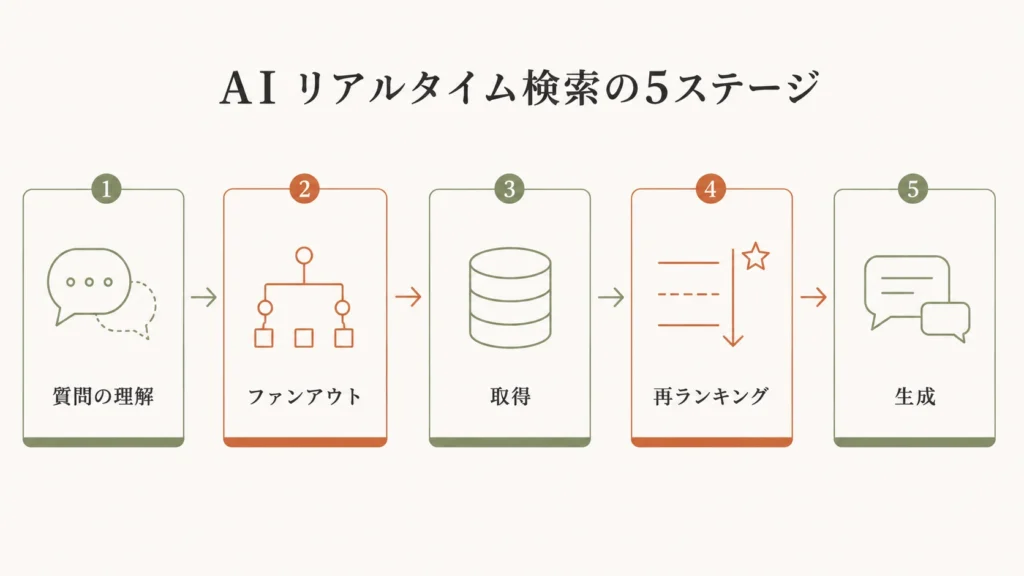
このパイプラインを見ると、「インデックスに登録されること」と「引用されること」がまったく別のことだと分かります。ステージ3(取得)はインデックスの話。ステージ4・5(再ランキングと生成)は、コンテンツの質の話です。
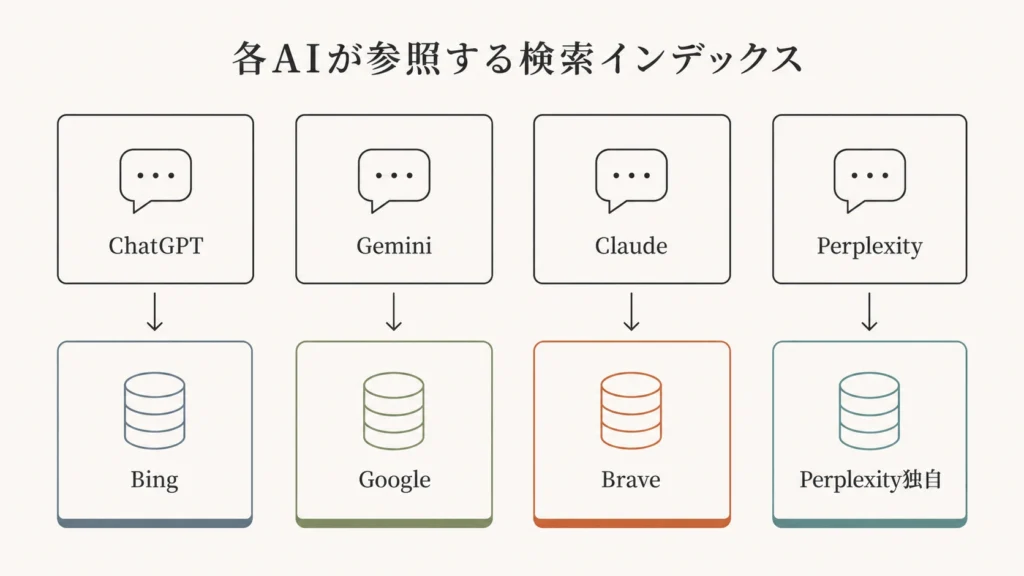
各AIはどのインデックスを参照しているか
ステージ3で参照するインデックスは、AIごとに異なります。
| AIチャットボット | 検索バックエンド | インデックス管理者 | 確認済み一次ソース |
|---|---|---|---|
| ChatGPT | Bing Search API+非公開メディアパートナー | Microsoft | OpenAI公式ヘルプセンター |
| Gemini | Google Search | Google公式ブログ | |
| Claude | Brave Search | Brave(独立系) | Anthropic公式サブプロセッサーリスト |
| Perplexity | 独自インデックス(旧:Bing) | Perplexity | Perplexity公式発表(2025年9月) |
管理者が違うだけでなく、各インデックスの特徴も異なります。
ChatGPT(Bing) は、BingのWebインデックスをベースにしつつ、OpenAIが個別契約したメディアパートナー(Axel Springer、Financial Times、Condé Nastなど)のコンテンツも参照します。TechCrunchの報道にあるように、提携先を非公開にしているAI企業もあります。
Gemini(Google) は、Google Search本体と同じインフラを共有しています。AI OverviewsとGeminiは同じ基盤の上に乗っているため、Google SEOで積み上げたE-E-A-Tや権威性シグナルが、4社の中で最もそのまま使えます。
Claude(Brave) は、Anthropicの公式サブプロセッサーリストへの追記(2025年3月)と、Claude APIのツール定義に含まれるBraveSearchParamsパラメータによって確認されています。BraveはGoogleやBingからライセンスを受けず、独自クローラーで構築した独立系インデックスです。GoogleやBingで上位でも、Braveには未登録というケースがあります。
Perplexity(独自) は、当初Bingに依存していましたが独自インフラを段階的に構築し、2025年9月に独自Search APIを公式発表しました。4社の中で唯一、検索インデックスを自社で完結させた構造です。
AIチャットボットは全クエリで検索を発動するわけではない。「〜とは何か」「〜の仕組みを教えて」といった概念系の質問には、モデルが記憶から回答することが多い。検索が発動しやすいのは「最新の〜」「〜のおすすめ」「〜vs〜」など、鮮度・比較が求められるクエリ。
インデックスに入ることと、引用されることは別の話
ここが多くのGEO解説が飛ばしているポイントです。
検索エンジンのランキングと、AIの引用は、別のシステムが決めています。AIはBingやBraveのインデックスから候補ページを取得した後、自分自身でそのページを読み、「このクエリへの回答に使えるか」を独自に再評価します(ステージ4のre-ranking)。
図書館の司書と研究アシスタントの違いで考えてみてください。司書(インデックス・ランキングアルゴリズム)は、キーワードに合う本を人気順に積み上げます。研究アシスタント(LLM)は、その積み上げられた本を実際に読んで、あなたの質問に本当に役立つ部分を探します。一番上の本が役に立つとは限りません。
ある実測データでは、AIが引用するURLとGoogleのトップ10の一致率は約12%と報告されています。ただしこれは単一の調査で、方法論の開示も限られているため、「方向性として正しい」程度に受け取るのが適切です。一次情報として言えるのは、インデックスへの登録と引用は別のステップで起きているということです。
インデックスは「候補に入るかどうか」の話。引用は「候補の中から選ばれるかどうか」の話。Bingで1位でも、ClaudeのBrave re-rankerに「引用に値しない」と判断されれば使われない。逆に、検索順位が低くても、クエリに直接答えている段落があれば引用される可能性がある。
第3層:引用選択(AIが何を回答に含めるか)
ステージ4(re-ranking)とステージ5(generation)で起きることが、GEOが実質的に効く層です。
Princeton・Georgia Tech共同研究としてACM SIGKDD 2024に掲載されたGEO原論文では、同じWebページに異なる最適化手法を適用して、AIの回答中での可視性変化を計測しています。
- 専門家の言葉・引用文の活用: 実在する専門家・公式ソースからの引用追加が最も効果が高く、可視性+41%。「〜によると」の形で一次情報を示すことが重要
- 統計・数値データの追加: 具体的な数値を含む記述は+32%の改善。「多くの場合」より「80%以上」のほうが引用対象になりやすい
- 出典・一次情報の明示: 参照元を明記したコンテンツは+30%の可視性向上。ソースなしの主張よりソース付きの主張が選ばれる
- 段落レベルの構造: 見出し・箇条書き・定義が整理されたページが抽出されやすい。自己完結した段落がひとつのクエリに答えている構成が理想
- クエリへの直接的な回答: 冒頭40〜60語以内でクエリに答えている段落が引用単位になりやすい
AIごとに引用の「性格」も異なる
118,000件のAI回答を分析したWhitehat SEOの実測データと、17.2百万件の引用を分析したYext Researchのデータを合わせると、各AIの引用傾向にはっきりした違いがあります。
- ChatGPT:1回答あたり平均7.92件を引用。Wikipediaへの依存が高く、権威ある出版メディアを重視する傾向
- Gemini:平均8.34件。公式サイトや機関サイトを優先。Google E-E-A-Tシグナルと最も連動しやすい
- Perplexity:平均21.87件と最多。引用率が高く、ニッチ・専門性の高いサイトにも機会がある。コンテンツの鮮度への反応も最も強い
- Claude:平均5.67件と最少。4社の中で最も保守的な引用傾向。ニュース・出版メディアへの依存率が最も高い(51%)
上記の要因は学術研究および複数の大規模実測データに基づく知見であり、各社が公式に「このコンテンツを引用する」と定めたアルゴリズムではない。GEOはまだ発展途上の領域で、断言できることは限られている。施策の効果を過大に主張するコンテンツには注意が必要。
結局、GEOは何を最適化しているのか
3層を整理すると、GEOで実際に動かせるのは第2層と第3層だけです。
第1層(トレーニングデータ) はコントロール不可。次のモデル更新を待つしかありません。
第2層(リアルタイム検索) でやるべきことは、各インデックスにクロールされ、登録されていることです。robots.txtのブロック解除、Brave Webmaster Toolsへの登録、Bing Webmaster Toolsの設定。こうした作業はSEOの基礎と重なります。
第3層(引用選択) でやるべきことは、引用される構造を作ることです。出典の明示、数値データ、専門家の引用、自己完結した段落構成。これらはライティングとコンテンツ設計の問題です。
「インデックスに入ること」と「引用されること」は、別々に対策が必要です。GEOはSEOを置き換えるものではなく、SEOの上に乗るものです。インデックス登録という前提はSEOと完全に共通しています。
まず第2層前半——各インデックスにクロールされ、登録されていること。次に第3層——re-rankerと生成モデルに「引用に値する」と判断されるコンテンツ構造・権威性・出典の明示。第1層のトレーニングデータはコントロール不可。施策を評価するとき、「これは何層に効くのか」を問う習慣を持つといい。
SEOの土台から整理したい方は、SEO独学ロードマップを参考にしてください。GEOの前提となるインデックス登録の話が、そこに整理されています。
日本語コンテンツへの補足
一点、正直に書いておきます。
ここまで紹介した研究・実測データは、ほぼ英語コンテンツを対象にしたものです。日本語での検索×日本語コンテンツに同じ知見がそのまま使えるかどうかは、現時点では検証データが少ない。
ただ、インデックスへの登録・クロール許可という第2層の前提条件は言語を問いません。コンテンツの構造や一次情報の明示という第3層の原則も、方向性として誤りではないと考えています。
Perplexityが自社インデックス発表時に述べたように——
「LLMs are powerful, but limited by static training data. With Sonar, we solved this by grounding answers in live web content.」
Perplexity AI, Introducing the Perplexity Search API, September 25, 2025
モデルが静的な学習データの限界を超えるためにリアルタイム検索を使う、という構造はすべての言語で共通です。日本語コンテンツのGEO可視性については、ニコルデジマで継続的に観察・発信していきます。
まとめ
GEOで動かせるのは3層のうち2層だけです。トレーニングデータ(第1層)はコントロールできません。検索インデックスへの登録(第2層)と、引用されるコンテンツ構造(第3層)が、実際に手を入れられる場所です。
「Googleで上位表示されればAIにも引用される」は成立しません。各AIは異なるインデックスを参照していて、インデックスの検索順位と引用選択は別のシステムが決めています。
ブランドオーナーの方には、この点を特に伝えたいと思っています。
GEOは新しい取り組みに見えますが、その土台は何年も前から変わっていません。きちんとインデックスされていること、権威性のある一次情報を書いていること、構造が明快なコンテンツを積み上げていること。これは全部、SEOの基本です。GEOの文脈で「新しい施策」として出てくるものの大半は、SEOをちゃんとやってきたブランドにとって、すでに持っている資産です。
新しいツールや設定を追いかける前に、まず自分のサイトが各インデックスにきちんとクロールされているかを確認してください。それだけで、GEOの準備の半分は終わります。結局、地道な積み上げが一番強い。それはAI時代になっても変わっていません。
GEOの施策を評価するとき、「これはどの層に効くのか」を問う習慣が、無駄な動きを減らす一番の近道だと思っています。
よくある質問
GEOとSEOは何が違うのですか?
SEOは検索エンジンの結果ページ(SERP)での順位を上げることを目的とします。GEOはAIチャットボットの回答にコンテンツが引用される確率を高めることを目的とします。ただしGEOはSEOを置き換えるものではなく、インデックス登録というSEOの基礎の上に乗るものです。
自分のサイトがAIに引用されているか確認できますか?
手動で確認するなら、各AIチャットボットに自分のサイトが扱うトピックを質問して、引用されているかを見る方法があります。体系的に追うには、Perplexity・ChatGPT・Gemini・Claudeそれぞれで定期的に計測するか、AI可視性の追跡ツールを使う方法があります。ただし引用は確率的なので、毎回同じ結果にはなりません。
BraveやBing Webmaster Toolsに登録する必要はありますか?
ClaudeがBrave Searchを使っている以上、Brave Webmaster Toolsへの登録はClaudeでの可視性に直接影響します。ChatGPTを対象にするならBing Webmaster Toolsも重要です。GoogleへのSEOだけで十分とは言えなくなっています。
日本語コンテンツはGEOで不利になりますか?
現時点では英語コンテンツを対象にした研究が大半で、日本語への適用は検証データが限られています。ただしインデックスへの登録やコンテンツ構造の原則は言語を問わないため、基本的なSEOと構造化されたコンテンツ設計が、現時点での最も確実な対策です。
GEOのために今すぐできることは何ですか?
まず各インデックスへのクロール許可を確認すること(robots.txtのチェック)。次にBrave Webmaster ToolsとBing Webmaster Toolsへの登録。そして既存コンテンツに出典・数値データ・専門家の言葉を追加することです。新規コンテンツを増やす前に、この土台を固めることをおすすめします。



コメント— COMMENTS